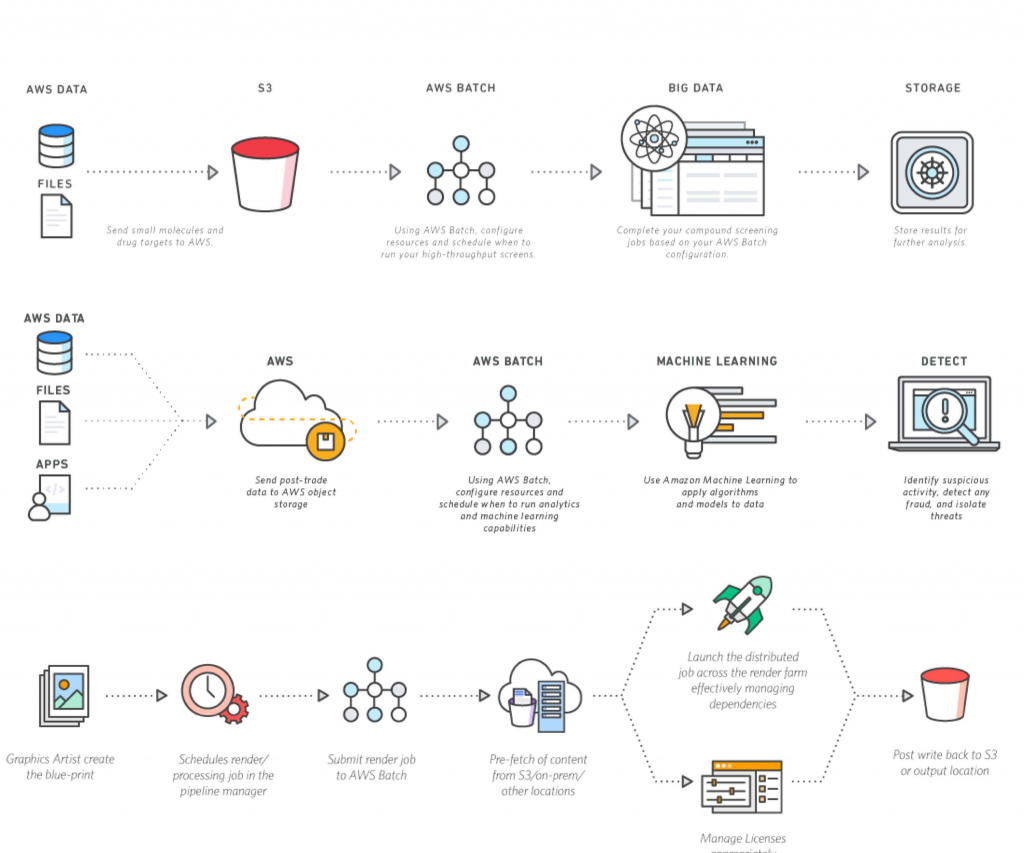
What exactly is a remote IoT batch job, and why should it matter to your organization? Essentially, its the backbone for managing and processing vast quantities of data generated by Internet of Things (IoT) devices, offering a scalable and efficient solution for a variety of industrial applications.
Setting up a remote IoT batch job on Amazon Web Services (AWS) requires a strategic approach, involving meticulous planning and flawless execution. This guide provides a comprehensive overview of the key steps to navigate this process successfully. Well explore the critical elements involved in harnessing the power of AWS for your IoT data processing needs.
The complexity of AWS IoT batch jobs can seem daunting at first glance. The concept, at its core, is surprisingly straightforward. It's a predefined task that runs automatically on AWS, designed to process the large volumes of data streaming from your IoT devices. Consider it a digital assembly line where each step is carefully orchestrated to transform raw data into actionable insights.
To better understand how remote IoT batch jobs work in AWS, consider the following example. This section walks you through a practical implementation of a remote IoT batch job. Imagine a scenario where a manufacturing company needs to process telemetry data from thousands of sensors.
| Aspect | Details |
|---|---|
| Definition | A remote IoT batch job on AWS is a pre-configured task designed to automatically process substantial volumes of IoT data. It's an automated workflow. |
| Purpose | Transforms raw IoT data into valuable insights, facilitating informed decision-making. |
| Functionality | Involves data collection, processing, analysis, and storage, enabling monitoring of equipment performance and predictive maintenance planning. |
| Benefits | Enhances efficiency, reduces operational costs, and improves data-driven decision-making across a manufacturing enterprise. |
| Common Use Cases | Industrial machine monitoring, predictive maintenance, optimizing production workflows and quality control. |
| Key Components | AWS Batch, compute environments, job queues, and job definitions. |
The initial step centers on defining the precise requirements of the batch job and carefully assessing the necessary resources. This involves a thorough understanding of the data volume, the complexity of the processing tasks, and the desired output. Careful resource allocation is critical to avoid performance bottlenecks and cost overruns.
Next, establish an AWS Batch compute environment and a job queue. The compute environment serves as the foundation for running your jobs, providing the necessary compute resources. The job queue manages the order in which jobs are executed, ensuring an organized and efficient workflow. Careful configuration of these components ensures optimal performance and scalability. The interplay between these two is critical for successful batch processing.
Crafting the batch job definition is a pivotal step. This definition outlines the specific tasks your job will perform, including the input data, the processing logic, and the desired output. The job definition essentially provides the blueprint for your automated data processing pipeline. The definition should incorporate any dependencies needed for the job to execute successfully, ensuring all software libraries and configuration files are accessible.
Once the job definition is complete, upload it to AWS and then submit the batch job. This initiates the automated data processing workflow. Monitoring the progress of the job is essential. AWS provides comprehensive tools for tracking the execution of your jobs, allowing you to identify and address any issues that may arise, to optimize performance, and to ensure the desired outcomes are achieved. Careful monitoring is vital for ensuring the success of your IoT data processing efforts.
A remote IoT batch job on AWS is, in essence, an automated system. It's designed to collect, process, analyze, and store large datasets, enabling informed decision-making and optimizing operational efficiency across a variety of industries. It acts as a digital command center, where raw data transforms into actionable insights. When managing a fleet of industrial machines, it provides a real-time view of their performance, identifying potential issues before they escalate.
Consider this scenario: A manufacturing company needs to process telemetry data from its thousands of sensors distributed across its production facilities. This data includes temperature readings, pressure levels, and machine performance metrics. The goal is to monitor equipment health, detect anomalies, and predict potential maintenance needs.
The first step involves defining the scope of the data processing tasks. What specific data needs to be analyzed? What transformations are required? What outputs are necessary to meet the company's objectives? This clarity is the bedrock upon which the batch job is built.
Next, the necessary resources are provisioned on AWS. This involves setting up an AWS Batch compute environment. This compute environment provides the processing power needed to handle the incoming data. A job queue is then configured to manage the processing tasks. The job queue acts as the control center, organizing the workload and ensuring an orderly flow of processing.
The next step is the creation of a batch job definition. This definition provides the precise instructions for the data processing workflow. This involves specifying the processing logic, the location of input data, and the desired format of the output data. The job definition serves as a roadmap for automated data processing.
With the job definition in place, the batch job is submitted to AWS. AWS then orchestrates the execution of the tasks. The system automatically processes the telemetry data, applying the defined transformations and analytics. The output of this process can include performance dashboards, anomaly reports, and predictive maintenance alerts.
The success of this process heavily depends on the companys ability to understand and apply best practices. Careful planning and execution are essential to avoid common pitfalls. When implemented effectively, remote IoT batch jobs on AWS provide a powerful, efficient, and scalable solution for processing and leveraging the vast amount of data generated by IoT devices.
There are several common pitfalls to avoid. One is inadequate resource allocation. Without sufficient resources, jobs can take an unreasonable amount of time to complete. Another is overlooking the significance of monitoring. Without diligent monitoring, issues can go unnoticed, and performance can degrade. Finally, data quality issues should be addressed early to avoid incorrect analysis. Robust error handling is critical to the reliability of the batch job.
This automated process enables companies to enhance operational efficiency, reduce expenses, and make data-driven decisions across their entire organization. By adopting AWS Batch and adhering to best practices, businesses can unlock the full potential of their IoT data, turning it into a strategic asset that drives innovation and growth. AWS Batch allows businesses to process massive data volumes without the need to provision and manage underlying infrastructure, ensuring scalability and cost-efficiency.
By adhering to the steps outlined in this guide, and by implementing the best practices, organizations can take full advantage of the power of AWS for their IoT data processing needs. Success depends on proper planning, intelligent execution, and consistent monitoring. With the correct approach, AWS Batch empowers businesses to process vast amounts of data, gain valuable insights, and boost operational efficiency.